Comparing Africa-centric Models to OpenAI’s GPT3.5

BY JADE ABBOTT, BONAVENTURE DOSSOU AND ROOWEITHER MBUYA
The recent release of OpenAI’s ChatGPT has turned the world upside-down, and with good reason. For the first time, the power of language models have been packaged into a tool that is ready for users to consume, and to play with.
While language models, such as ChatGPT, are extremely impressive, they often show limited capabilities for low resourced languages. Masakhane and others have highlighted time and time again, that many multilingual language models are trained on dangerous, offensive and frankly garbage data (Caswell, 2022), and that the models do not perform well on many languages – especially African languages.
We decided toy with ChatGPT to check out it’s capabilities for the Zulu language. Results were mixed and often hilarious:
After a few successes and failures, we decided it’s time we did a proper benchmark of some available Africa-centric models to OpenAI’s models. Given ChatGPT API is not available as of yet, we’re comparing to GPT3.5. GPT3.5 is an OpenAI language model that is the same as ChatGPT except that it’s not trained to do dialogue.
We decided to benchmark GPT3.5 on 2 common NLP tasks: Named Entity Recognition and Machine Translation.
Named Entity Recognition
Named Entity Recognition is an important task in NLU which allows us to extract things such as names, places and datetimes from text. It is used widely in conversational AI, as well as social media analysis.
For example, in the text: “I hear that Pelonomi Moiloa is the CEO of Lelapa AI”, an NER model should recognise that “Pelonomi Moiloa” is a person and that “Lelapa AI” is an organisation.
We benchmarked on the MasakhaNER2.0 dataset, a multilingual and human-annotated NER dataset; covering 21 African languages and 4 entities (persons, organisations, locations, and dates). We chose 3 Africa-centric models to benchmark against, namely AfroXLMR-Base, AfroXLMR-Large, and AfroLM and compared them to GPT3.5. All models were fine-tuned on the MasakhaNER dataset, and then evaluated on the test set.
| Model | Average F1-Score across all categories |
| GPT3.5 | 87 |
| AfroXLMR-Base | 88.4 |
| AfroXLMR-Large | 91.5 |
| AfroLM | 86.3 |
While GPT3.5 did perform well, the Africa-centric language models AfroXLMR-Base and AfroXLMR-Large performed better. AfroLM performed similarly to GPT3.5, which is impressive given it’s a much much smaller model (only 236 million parameters) compared to the extremely large GPT3.5 (175 billion parameters).
Machine Translation
Machine translation is one of the most well known NLP tasks, while also being the most difficult. Google Translate has been extremely successful in well-resourced languages such as French, but has historically had difficulty with African languages.
We had a look at how ChatGPT was performing on a couple of examples, and were not impressed with the results:
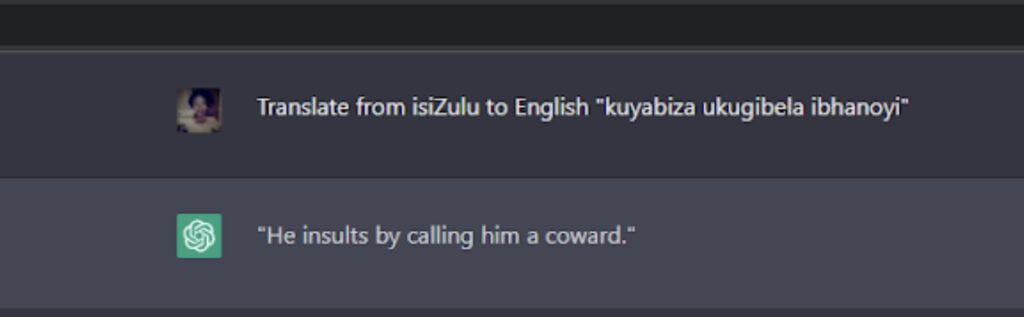
The above is meant to translate to: “It is expensive to take a flight”. Not even remotely related. The back-translation wasn’t great either:
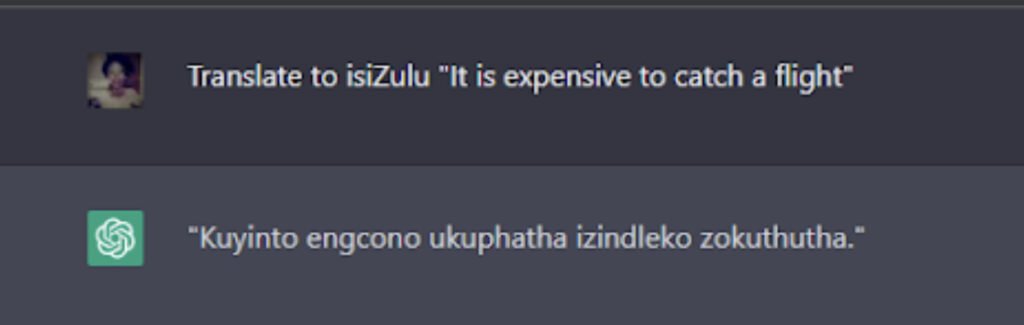
Here, ChatGPT translated “It is expensive to catch a flight” into “It is better to manage the transportation costs” in Zulu.
For some quantitative results, we opted to use GPT3.5 again. We used the MAFAND translation dataset, a multilingual and human-annotated news datasets; covering 20 African languages + French & English. Here we compare the performance of GPT3.5 to M2M100 – a pretrained model, (while not being Africa-specific) is focused on multilinguality, especially for low-resourced languages and included some African languages in it’s pre-training.
We use the BLEU score and ChrF score to compare performance. They’re both popular metrics to help evaluate machine translation systems (despite their flaws). The larger the numbers the better.
| Model | BLEU | ChrF |
| GPT3.5 | 0 | 0.13 |
| M2M100 | 21.2 | 51.2 |
| Model | BLEU | ChrF |
| GPT3.5 | 0 | 0.22 |
| M2M100 | 38.0 | 55.5 |
From the above tables it appears that GPT3.5 is not suitable at all for translation of Zulu compared to existing models. We doubted these numbers because it seemed extremely surprising that GPT3.5 would achieve a BLEU 0f 0 (to be honest, it was very close to 0 rather than 0 itself). For some context, here are a few samples from the translations:
| Original Sentence | ngibona ukuthi kuningi okungenziwa ukusiza abantu kulesi sikhungo. |
| Target Translation | i feel like there could be more done to help people within this industry. |
| GPT3.5 Predicted Translation | i skipped around trying to use as much of the plant material as i could. |
| M2M100 Predicted Translation | i see that there’s a lot you can do to help people at this establishment. |
What is going on GPT3.5?! M2M100 does a pretty good job of translating to the correct target sentence, but GPT3.5 is spewing out completely unrelated garbage. No wonder the metrics are so low. Let’s look at another!
| Original Sentence | itanzania iphakathi kwamazwe anohlaka lwezomthetho oluphuma phambili lokuthuthukiswa kukagesi ovuselelekayo, ngokukambambiqhaza. |
| Target Translation | tanzania is among the countries with the best legal framework on renewable energy development, according to a stakeholder. |
| GPT3.5 Predicted Translation | south africa is a member of various international bodies that impose different standards and conformity |
| M2M100 Predicted Translation | tanzania is an intermediate of the nation’s legacy that outweighs the development of renewable gas, in particular. |
Wow. This one is fascinating. Tanzania became South Africa somehow – one can’t help but laugh. And just for good measure, we’ve checked the reverse direction of translation where the models translate from English to Zulu (typically a much more difficult task).
| Original Sentence | and it means what? |
| Target Translation | bese kusho ukuthini? |
| GPT3.5 Predicted Translation | besebenza ngesicabange |
| Backtranslation into English | working with imagination |
| M2M100 Predicted Translation | futhi kusho yini? |
| Backtranslation into English | and what does it mean? |
As GPT3.5 has translated: it seems to be “working with imagination” itself, completely inventing unrelated content as translations. It’s not actually unsurprising that GPT3.5 doesn’t compare to M2M100. After all, M2M100 is a multilingual translation specific language model, where as GPT3.5 is a general purpose one.
Summary
Despite the power of OpenAI’s language models, they’re still not achieving the accuracy of low-resource and Africa-centric language models, on both simple tasks such as Named Entity Recognition or complex tasks such as Machine Translation. A demonstration of the huge value of context-specific AI work.
I have never laughed so hard, unprovoked! Thus said, the guys who develop AI tools, generally have an American perspective on the world and other cultures. They are creating solutions based on their frustrations and viewpoints. The fact that it has a global audience, is generally a surprise bonus. They are not designing anything with Africa in mind, they never have. The sooner we accept this, the faster we can move on to developing our own platforms.