InkubaLM: A small language model for low-resource African languages

As AI practitioners, we are committed to forging an inclusive future through the power of AI. While AI holds the promise of global prosperity, the challenge lies in the resources required for large models, which are often out of reach for the majority of the world and fail for the languages in those contexts. Open-source models have attempted to bridge this gap, but more can be done to make models cost-effective, accessible, and locally relevant. Introducing InkubaLM (Dung Beetle Language Model) – a robust, compact model designed to serve African communities without requiring extensive resources. Like the dung beetle, which moves 250 times its weight, InkubaLM exemplifies the strength of smaller models. Accompanied by two datasets, InkubaLM marks the first of many initiatives to distribute the resource load, ensuring African communities are empowered to access tools such as Machine Translation, Sentiment Analysis, Named Entity Recognition (NER), Parts of Speech Tagging (POS), Question Answering, and Topic Classification for their languages.
Model
To address the need for lightweight African language models, we introduce a small language model, InkubaLM-0.4B, trained for the five African languages: IsiZulu, Yoruba, Hausa, Swahili, and IsiXhosa. During training, we also include English and French.
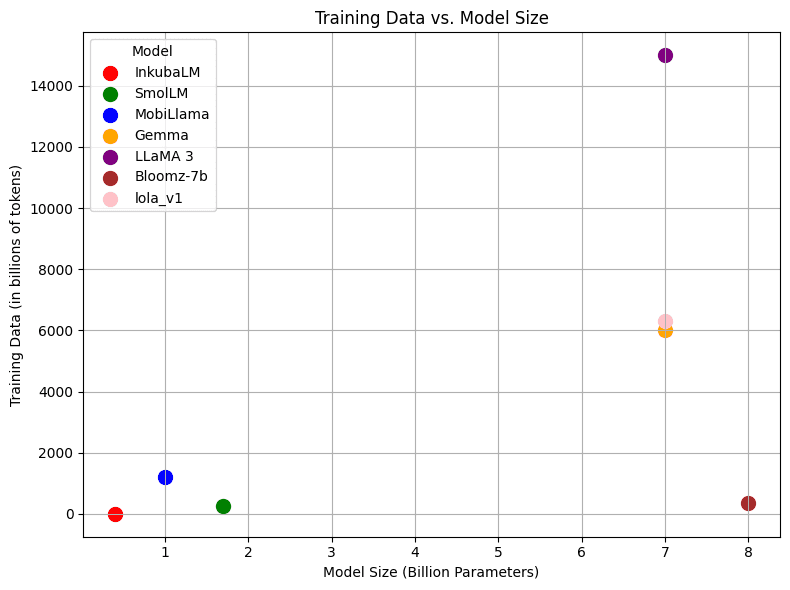
InkubaLM-0.4B has been trained from scratch using 1.9 billion tokens of data for the five African languages, along with English and French data, totalling 2.4 billion tokens of data. Similar to the model architecture used for MobileLLM, we trained InkubaLM with a parameter size of 0.4 billion and a vocabulary size of 61788. The figure below shows the training data and model sizes of different public models. When we compare our model in terms of these parameters, we find that our model is the smallest in terms of size and has been trained using the smallest amount of data compared to other models.
Datasets
We also present two datasets, Inkuba-Mono and Inkuba-Instruct, for five widely-spoken African languages: Swahili, Yoruba, IsiXhosa, Hausa, and IsiZulu, with approximately 364 million speakers.
Inkuba-Mono Dataset
The Inkuba-Mono is a monolingual dataset collected from open-source repositories in five African languages to train the InkubaLM model. We collected open-source datasets for these five African languages from repositories on Hugging Face, Github, and Zenodo. After preprocessing, we used 1.9 billion tokens of data to train the InkubaLM models.
Inkuba-Instruct Dataset
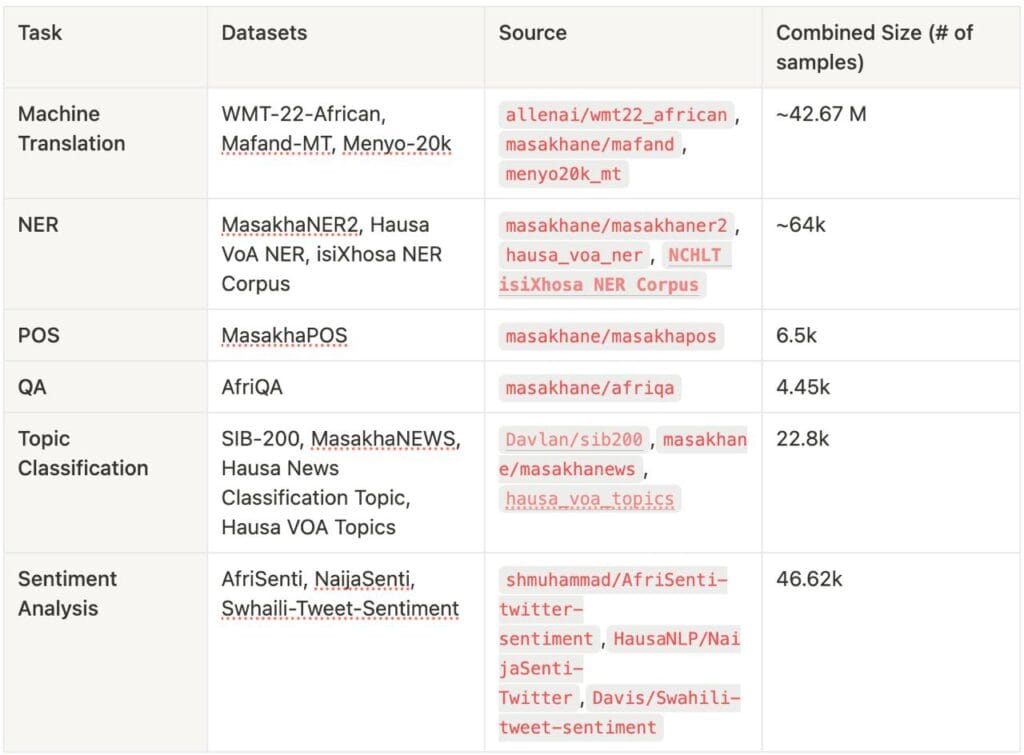
Our instruction dataset focused on five tasks: Machine Translation, Sentiment Analysis, Named Entity Recognition (NER), Parts of Speech Tagging (POS), Question Answering, and Topic Classification. For each task, we covered five African languages: Hausa, Swahili, IsiZulu, Yoruba, and IsiXhosa. The table below summarizes the datasets and their sources, we used for each task:
We created prompt templates for the above tasks initially in English and humanly translated them into the African languages of interest. For the machine translation task, we built the instruction datasets in two directions (xx→eng and eng→xx; where xx represents the African language). Regarding the Topic Classification and Sentiment Analysis tasks, we translated and used the labels in the respective target languages (i.e., if the label is politics then for Swahili we use the Swahili translation of politics , if we switch to Hausa, we use the Hausa translation of politics). For tasks such as NER and POS we did not perform this mapping, as the labels are language agnostic. After generating the instruction inputs and targets for each task, for each language, we merged them all together and added a task column to make it easier to filter at a later stage. We split into train , dev and test sets.
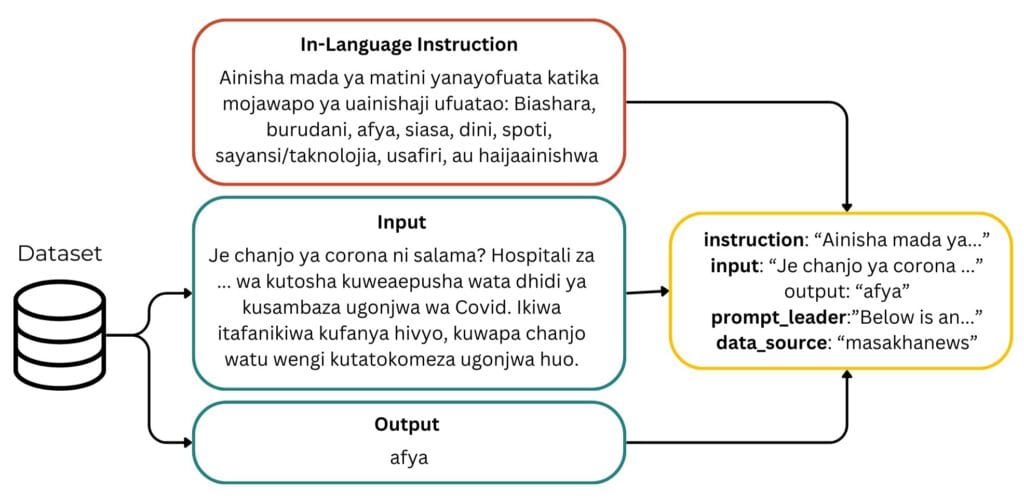
Across all languages, merging tasks, we created a training instruction dataset of 148M samples, a validation set of 65M samples, and a testing set of size 55M samples. Below is an example of how we converted the Swahili Topic Classification dataset into an instruction dataset.
NOTE: We’re withholding the test set for now because we’ll be running a Zindi competition using the dataset soon — we will release the test set afterwards. 🎉
Results
To assess our model’s performance, we compared it with other open-source models. We selected a sentiment analysis task from our Inkuba-instruct dataset and two **IrokoBench** tasks: multi-choice knowledge-based QA (AfriMMLU) and natural language inference (AfriXNLI). We chose different base models based on the number of parameters and training data size to compare with our model. It is important to note that we didn’t include instruction-tuned models like Aya because our InkubaLM is not an instruction-tuned model. It is also worth noting that we have focussed on the ability of the models to perform in our language of interest. We aim to illustrate the potential of low resource in the case of specificity rather than generalist capability as for many resource-constrained contexts, many of the capabilities of larger, more extensive models are typically not used in any case.
Sentiment Analysis
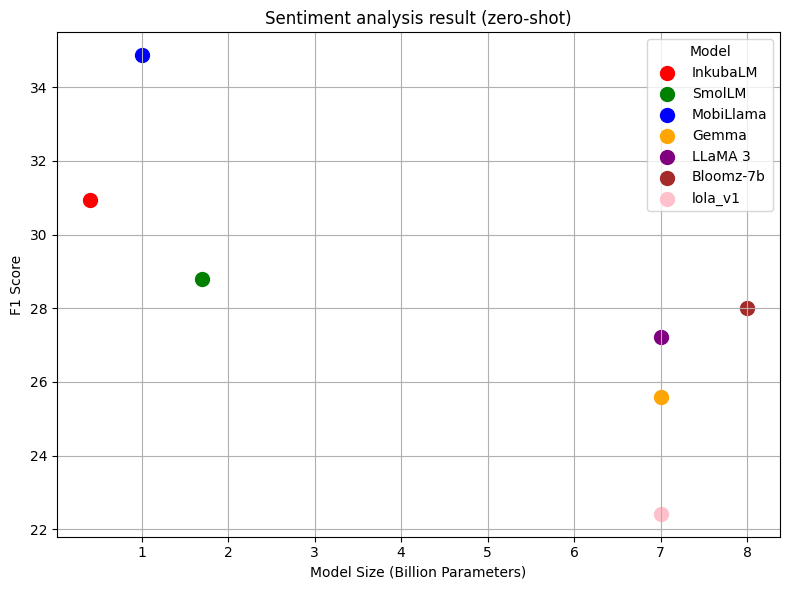
The following result shows the average F1 score of different models in the sentiment analysis task using a zero-shot English language prompt for Swahili, Hausa, and Yoruba. As we can see from the figure, our model outperforms all models in sentiment analysis regardless of parameter and training data size except for MobiLlama.
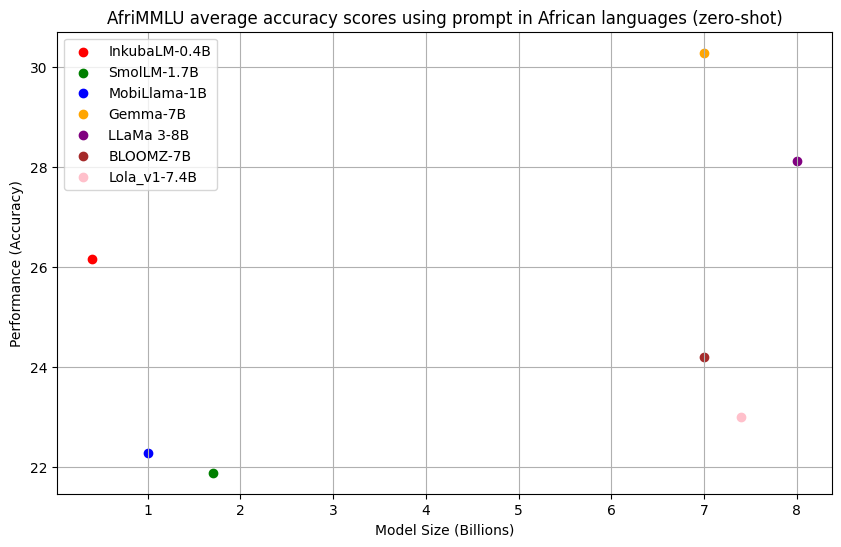
AfriMMLU
In the AfriMMLU task, our model outperformed four out of six models on average regardless of parameter and training data size using prompts in five African languages. While Gemma-7B and LLaMa 3-8B models demonstrate better results than other models in the AfriMMLU task, the models are significantly larger.
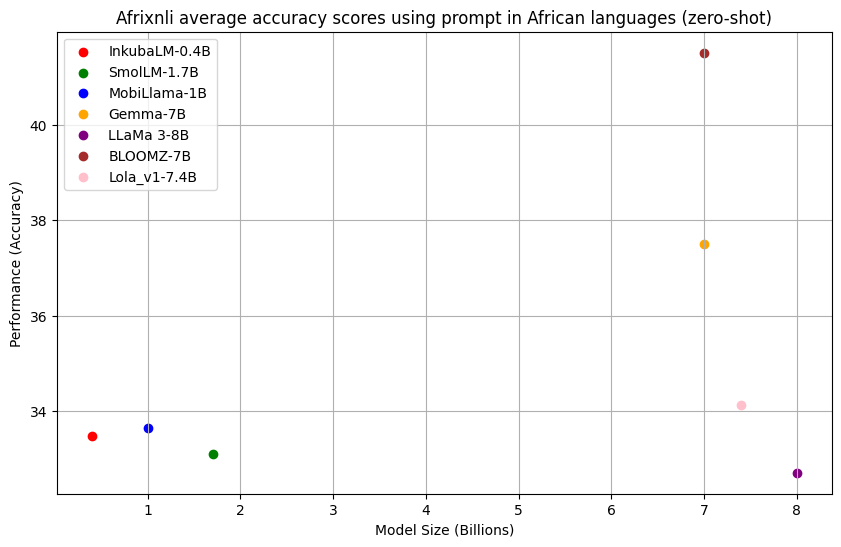
AfriXNLI
In the AfriXNLI task, as shown in the figure below, our model outperformed SmolLM -1.7B and LLaMA 3-8B models on average when using prompts in five African languages (zero-shot).
Where to from here?
The Inkuba release aims to enhance language model capabilities for African languages through two key initiatives. First, InkubaLM is introduced as a new model that can be further trained and developed to improve functionality in a variety of tasks for the languages in question. Second, the Inkuba datasets are available to enhance the performance of existing models. Given that conventional large language models perform poorly with these languages, Inkuba provides NLP practitioners with effective options to achieve robust functionality for the five targeted languages.
InkubaLM is an autoregressive model trained to predict the next token, so it can be used for a variety of tasks, such as text generation. It can also be used as a base to perform any downstream NLP tasks using zero-shot or few-shot learning. To get better performance in downstream tasks, we recommend users fine-tune the model using instruction datasets. Our model can be loaded using CPU/GPU/Multi GPU, so it can even be run on a laptop.
The Inkuba-Mono dataset can be utilised to train language models to perform tasks that require monolingual datasets. The Inkuba-instruct dataset can be utilised to instruct fine-tune any language model for the five African languages of interest. This would then allow those models to perform tasks such as machine translation, sentiment analysis, news classification, part of speech tagging, etc.
Conclusion
In this blog post, we introduced InkubaLM, a compact yet powerful multilingual language model designed for low-resource African languages. Alongside InkubaLM, we present two datasets: the Inkuba-Mono dataset and the Inkuba-Instruct dataset. Our model achieves performance levels comparable to those of larger models trained on extensive datasets with a large number of parameters. Lelapa AI champions smaller models as a pathway to equity. By focusing on model specificity, InkubaLM demonstrates the ability to meet or surpass the efficacy of larger models using significantly less data. In resource-constrained contexts, models like InkubaLM offer more practical and efficient solutions for developing and deploying NLP applications. In the future, we aim to showcase the additional benefits of smaller models, such as energy efficiency and improved interpretability. These advantages make smaller models the preferred choice for a sustainable and safer future for NLP development.
Access our models and dataset below 👇🏽
InkubaLM: https://huggingface.co/lelapa/InkubaLM-0.4B
Inkuba-mono dataset: https://huggingface.co/datasets/lelapa/Inkuba-Mono
Inkuba-Instruct dataset: https://huggingface.co/datasets/lelapa/Inkuba-instruct
Acknowledgments
We’d like to thank Microsoft AI4Good lab for the compute credits to train the above model. This work would not have been possible without your sponsorship.